MySQL이 SEQUENCE를 지원하지 않는 이유
0. JPA IDENTITY 전략 사용에 대한 의문
회사에서 batch insert 사용을 위해 application.yml에 batch 설정을 했는데도 배치 INSERT가 동작하지 않았다.
spring:
jpa:
properties:
hibernate:
jdbc:
batch_size: 50
order_inserts: true
설정은 맞는데 왜 안 되는 걸까?
원인을 찾아보니 MySQL + JPA 조합에서 거의 관행처럼 쓰이는 GenerationType.IDENTITY가 문제였다.
IDENTITY 전략은 AUTO_INCREMENT에 의존하기 때문에, INSERT가 실행되어야만 ID를 알 수 있다.
Hibernate는 영속성 컨텍스트에서 엔티티를 관리하려면 PK가 필요한데, persist() 시점에 PK가 없으니 쓰기 지연을 포기하고 즉시 INSERT를 실행한다.
batch_size를 아무리 키워도 쿼리는 한 건씩 나간다.
해결책은 SEQUENCE 전략이다. 시퀀스라면 INSERT 없이 nextval()로 ID를 미리 채번할 수 있고, 실제 INSERT는 flush 시점에 배치로 묶을 수 있다.
트랜잭션이 롤백되더라도 시퀀스는 non-transactional하게 동작하므로, gap만 남길 뿐 다른 트랜잭션에는 영향을 주지 않는다.
그런데... MySQL에는 시퀀스가 없다.
JPA는 이에 대한 대안으로 채번용 테이블을 만들어서 채번할 때 마다 해당 테이블의 row를 X-Lock을 잡고 UPDATE한다.
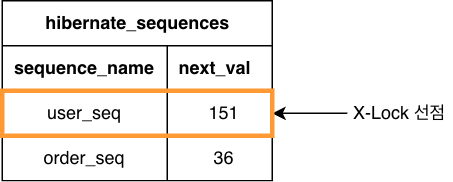 즉, 여러 스레드에서 동시에 채번을 시도하면 동시성 문제가 생길 수 있다.
즉, 여러 스레드에서 동시에 채번을 시도하면 동시성 문제가 생길 수 있다.
이러한 제약 덕에 MySQL + JPA 조합은 IDENTITY를 사용할 수 밖에 없는 구조다.
왜 MySQL은 이런 구조를 가지게 된걸까? PostgreSQL과 함꼐 비교해보려 한다.
1. 태생의 차이
PostgreSQL (1986)
PostgreSQL은 UC Berkeley의 Michael Stonebraker가 시작한 프로젝트다.
그는 이미 최초의 관계형 데이터베이스 중 하나인 INGRES를 만든 인물로, "처음부터 다시 만든다면?" 이라는 질문에서 POSTGRES(POST inGRES)개발을 시작했다.
학계에서 만들기 시작한 만큼 "빠르게 동작하는 것"보다 "올바르게 동작하는 것"을 중시했다.
사용자 정의 타입, 테이블 상속, 규칙 시스템 등 SQL 표준을 충실히 구현하면서도 확장성(extensibility)을 1급 시민으로 설계했다.
시퀀스 같은 독립적인 데이터베이스 오브젝트를 지원하는 것도 이 철학의 연장선이다.
MySQL (1995)
MySQL은 Michael "Monty" Widenius가 스웨덴에서 웹 애플리케이션을 위해 만든 경량 데이터베이스다.
기존에 사용하던 mSQL이 인덱스를 지원하지 않자, mSQL 개발자에게 자신의 ISAM 핸들러와 통합을 제안했지만 거절당했고, 직접 만들고자 했다.
설계 철학은 명확했다: "Simple, Fast, Free".
당시 웹은 폭발적으로 성장하고 있었고, 개발자들에게 필요한 건 학문적 완결성이 아니라 당장 돌아가는 빠르고 단순한 DB였다.
초기의 MySQL은 트랜잭션이나 시퀀스 같은 "무거운" 기능을 과감히 생략하고, 읽기 성능과 설치 편의성에 집중했다.
AUTO_INCREMENT 하나로 PK 생성을 해결한 것도 이 맥락이다. 별도 오브젝트 없이 테이블 컬럼 속성 하나로 끝나는 단순함을 더 중요시 했다.
Reference
2. 아키텍처의 차이: 2-Tier vs 모놀리식
이러한 철학의 차이는 아키텍처까지 영향을 미쳤다.
MySQL: Server Layer + Storage Engine Layer (2-Tier)
MySQL은 두 개의 독립된 계층으로 나뉘어 있고, Handler API라는 인터페이스로만 소통한다.
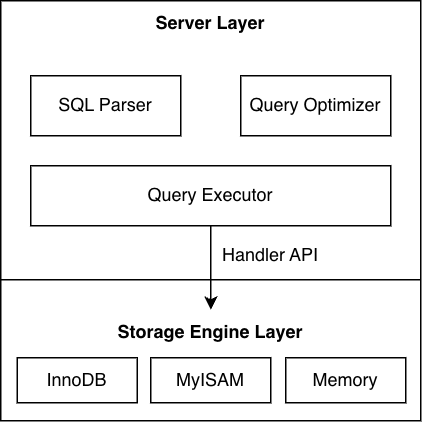
- Server Layer: 커넥션 처리, SQL 파싱, 옵티마이징, 쿼리 실행
- Storage Engine Layer: 실제 데이터 저장/조회, 인덱싱, 트랜잭션, 캐싱
- Handler API: C++ 추상 클래스로 정의. 각 엔진이 상속구조 (InnoDB →
ha_innobase, MyISAM →ha_myisam)
이 구조 덕분에 MySQL은 스토리지 엔진을 하나의 DB 내에서 테이블 단위로 교체할 수 있다.
PostgreSQL: 단일 통합 엔진 (모놀리식)
PostgreSQL는 MySQL처럼 엔진을 교체하는 개념이 없다. 단일 엔진으로만 동작하며 트랜잭션, ACID, 외래 키, MVCC가 내장되어 있다.
대신 extension을 통해 기능을 확장하는 방식을 사용한다. (커스텀 연산자, 인덱스(GIN, GiST, BRIN), 확장(PostGIS, pg_trgm 등))
Reference
3. 결론 - MySQL이 SEQUENCE를 지원하지 않는 이유
드디어 본론으로 왔다. 이러한 구조가 어째서 SEQUENCE를 지원할 수 없는 걸까?
Handler API는 오직 "테이블"만 안다
Handler API의 핵심 문제는, handler 인스턴스가 반드시 TABLE 객체에 바인딩된다는 것이다.
static handler *innobase_create_handler(TABLE *table) {
return new ha_innobase(table);
}
API 메서드 전체가 테이블/행 조작이다:
| 카테고리 | 메서드 |
|---|---|
| 테이블 열기/닫기 | ha_open(), ha_close(), ha_create() |
| 풀 스캔 | ha_rnd_init(), ha_rnd_next() |
| 인덱스 접근 | ha_index_read_map(), ha_index_next() |
| 행 변경 | ha_write_row(), ha_update_row(), ha_delete_row() |
get_next_sequence_value()나 create_sequence() 같은 메서드는 존재하지 않는다.
API의 명세 자체가 "테이블 열고, 행 읽고, 행 쓰고, 테이블 닫기"가 전부다.
SEQUENCE는 테이블이 아닌 독립 객체다
SEQUENCE는 SQL:2003 표준에 정의된 독립적인 데이터베이스 객체다.
어떤 테이블에도 종속되지 않고, 여러 테이블이 공유할 수 있으며, 트랜잭션 롤백에도 값이 되돌아가지 않는다.
이것을 MySQL의 2-tier 구조에 넣으려면 두 가지 선택지가 있다.
선택지 A: Server Layer에 구현
Server Layer에서 시퀀스 상태 관리
↕ (트랜잭션 경계 불일치!)
InnoDB에서 INSERT 실행
시퀀스 상태 업데이트와 사용자의 InnoDB INSERT가 서로 다른 트랜잭션 도메인에 존재하게 된다.
둘 사이에 크래시가 발생하면 일관성이 깨지고, InnoDB의 redo log를 통한 크래시 복구에 시퀀스 상태가 참여할 수 없다.
선택지 B: Storage Engine Layer에 구현
이 방식은 Handler API에 시퀀스 관련 가상 메서드를 추가해야 하고, 이로 인한 모든 스토리지 엔진의 수정을 요구한다.
InnoDB, MyISAM, ... 각각이 독립적으로 SEQUENCE 시맨틱스를 구현해야 한다.
이미 AUTO_INCREMENT도 엔진마다 동작이 다른 상황에서 또 다른 분기가 발생한다.
AUTO_INCREMENT가 가능했던 이유
AUTO_INCREMENT는 SEQUENCE와 달리 테이블에 종속적이기 때문에 Handler API와 충돌하지 않는다:
- InnoDB: 클러스터드 인덱스 안에 카운터 저장, redo log로 영속화
- MyISAM:
.MYI파일 헤더에 카운터 저장 - Memory: 테이블 메타데이터에 카운터 저장
각 엔진이 자기 테이블의 일부로 관리하므로 기존 API 안에서 자연스럽게 동작한다. 즉, AUTO_INCREMENT는 "테이블의 속성"이라 Handler API에 맞지만, SEQUENCE는 "독립 객체"라 맞지 않는다.
PostgreSQL에서는 왜 자연스러운가
PostgreSQL에서 시퀀스는 pg_class 시스템 카탈로그에 relkind = 'S'로 등록되는 1급 릴레이션이다.
즉, 테이블, 인덱스 같은 개념과 동등한 자격으로 취급된다.
PostgreSQL은 엔진 추상화가 없으므로, executor가 테이블이든 시퀀스든 동일한 내부 인프라를 통해 직접 접근한다.
MariaDB의 우회적 해결책: "시퀀스를 테이블인 척 하기"
MariaDB는 기존 2-tier 아키텍처를 깨지 않고 해결했다. 시퀀스를 항상 1행만 가진 테이블로 위장한 것이다.
CREATE SEQUENCE seq1;
-- 내부적으로 단일 행 테이블 생성 (InnoDB/Aria 기반)
-- 컬럼: next_not_cached_value, minimum_value, maximum_value,
-- start_value, increment, cache_size, cycle_option, cycle_count
JPA가 MySQL을 SEQUENCE로 사용할때와 거의 유사한 방식이다.
하지만 MariaDB의 방식은 엔진 수준에서 직접 관리하기 때문에 오버헤드가 상대적으로 적다.
6. 그 외 차이점
MVCC 구현
| MySQL (InnoDB) | PostgreSQL | |
|---|---|---|
| 방식 | 최신 버전만 테이블에 저장, 구버전은 Undo Log에서 복원 | 모든 버전을 힙 테이블에 직접 저장 |
| 정리 | 백그라운드 Purge 쓰레드가 자동 정리 | VACUUM 필요 (autovacuum) |
| 운영 부담 | 낮음 (자동) | 높음 (튜닝 필요) |
| 읽기 성능 | Undo log 복원 오버헤드 | 직접 읽기 → 읽기 집중 워크로드에 유리 |
타입 시스템 엄격성
- MySQL: 역사적으로 공격적 암묵적 캐스팅. 문자열 컬럼과 숫자 비교 시 조용히 캐스팅 -> 잘못된 결과 반환 가능
- PostgreSQL: "암묵적 변환이 놀라운 결과를 만들어서는 안 된다" -> 타입 불일치 시 에러
7. 두 DB는 서로 닮아가고 있다
컴파일 언어와 인터프리터 언어가 이제는 경계가 거의 허물어졌듯이, DB 또한 비슷한 양상을 띈다.
MyISAM → InnoDB: 스토리지 엔진의 전환
MySQL의 정확성 방향 전환은 Oracle 인수 이전부터 시작되었다. 가장 상징적인 사건은 기본 스토리지 엔진의 교체다.
초기 MySQL의 기본 엔진이었던 MyISAM은 MySQL 초기 철학의 결정체였다.
- 트랜잭션 없음, 테이블 레벨 잠금만, 크래시 복구 없음, 외래 키 없음
- 대신 읽기가 빠르고 단순
그런데 2010년 12월에 MySQL 5.5에서 드디어 기본 엔진이 InnoDB로 전환된다.
트랜잭션 없는 MyISAM에서 InnoDB로의 전환은, MySQL이 속도 우선에서 ACID를 준수하는 방향의 전환점이라고 생각한다.
Oracle 인수 이후 가속된 변화
Oracle에 인수되고 나서는 더 공격적으로 변화하기 시작했다.
MySQL 5.7 (2015):
STRICT_TRANS_TABLES기본 활성화 — 잘못된 데이터 삽입 시 에러 (과거: 조용히 잘라냄)ONLY_FULL_GROUP_BY기본 활성화 — SQL 표준/PostgreSQL 동작과 일치NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO기본 활성화
MySQL 8.0 (2018):
- Window Functions, CTE 등의 SQL 표준 기능 추가
- AUTO_INCREMENT 카운터 영속화 (15년 묵은 버그 수정)
- JSON, GIS 기능 강화
- 기본
innodb_autoinc_lock_mode을 2(interleaved)로 변경 -> 동시성 향상
정리
지금까지 살펴본 내용은 정리하면 다음과 같다.
| 항목 | MySQL | PostgreSQL |
|---|---|---|
| 철학 | 성능 > 기능 > 정확성 | 정확성 > 기능 > 성능 |
| 아키텍처 | 2-tier (Server + 플러거블 엔진) | 모놀리식 (단일 통합 엔진) |
| 연결 모델 | Thread (경량, 공유 메모리) | Process (격리, 안전성) |
| PK 생성 | AUTO_INCREMENT (테이블 속성) | SEQUENCE (독립 객체) |
| MVCC | Undo Log (자동 정리) | Heap 직접 저장 (VACUUM 필요) |
| 레플리케이션 | Binary Log (별도 메커니즘) | WAL (크래시 복구와 동일) |
| 타입 시스템 | 역사적으로 느슨 (수렴 중) | 엄격 |
| SQL 표준 | 일탈 다수 (수렴 중) | 거의 완전 준수 |
| 확장성 | 스토리지 레벨 (엔진 교체) | 시맨틱 레벨 (타입, 연산자, 인덱스) |
결론
처음의 질문으로 돌아가자. batch_size: 50을 설정했는데 왜 배치 INSERT가 동작하지 않았을까?
MySQL의 2-tier 아키텍처에서 Handler API는 테이블 단위로만 동작하기 때문에, 특정 테이블에 종속되지 않는 시퀀스는 Server Layer에 넣어도, Storage Engine Layer에 넣어도 깔끔하게 맞지 않는다.
시퀀스가 없으니 IDENTITY 전략을 쓸 수밖에 없고, IDENTITY는 INSERT 전에 PK를 채번할 수 없으니 쓰기 지연이 원천적으로 불가능하다.
설정의 문제가 아니라 아키텍처의 차이였다.